Buy me that look (From research paper to working application)
Objective
Have you ever searched for a product, like a t-shirt, and found one you loved? But when you clicked on it, you saw a model wearing not just the t-shirt but also perfectly matching pants, cool accessories like glasses, and a stylish handbag. Suddenly, you wanted to buy the whole look.
Or maybe you admire how certain celebrities dress and want to replicate their style but don't know where to find the exact products.
If you've experienced either of these situations, don't worry. The objective of this application is to solve this problem.
The aim of the application is to detect various types of wear, such as topwear, bottomwear, footwear, eyewear, and handbags from an image. It will then recommend similar products available on Myntra that you can buy to complete the look.
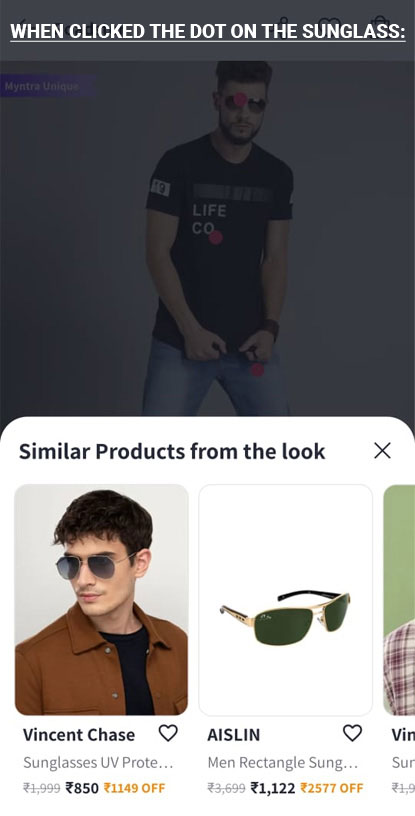
Here is the picture of how myntra app uses this feature:
It shows dot on detected objects and when any dot is clicked, similar products are shown.

Inspiration
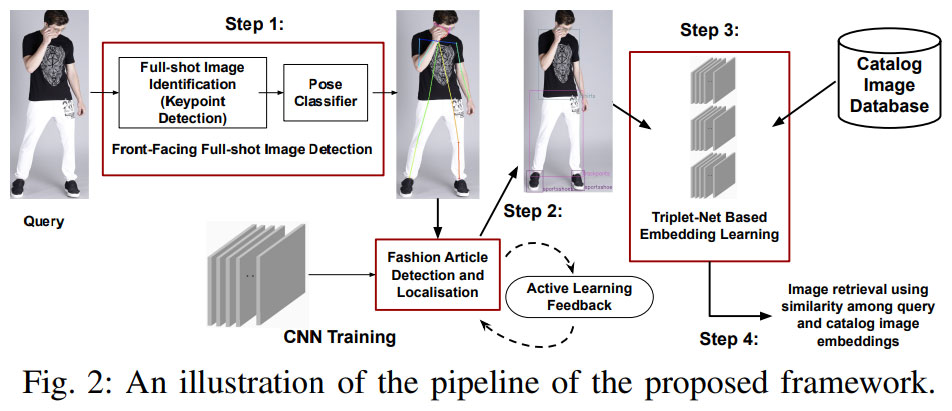
Inspiration is taken from this research paper from myntra - [ Link here ]
This below is a picture illustrating approach proposed in the paper:
Changes made by me in this proposed approach for building my application
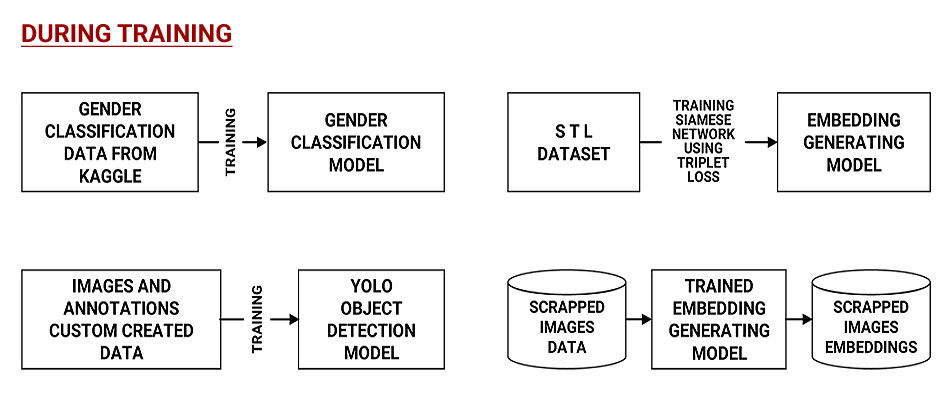
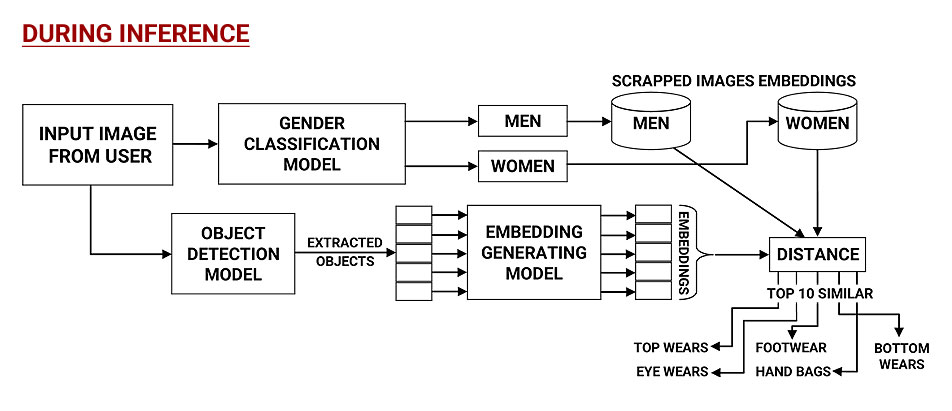
ADDITION OF NEW COMPONENT:
I decided to add a Gender classifier in the pipeline also because it would help us search similar products from only the products that are for that gender.
REMOVAL OF POSE DETECTION COMPONENT:
I want to give users of my application flexibility to provide half shot photos also and not just full shot. Even if it is a half shot photo, then also my models will detect the type of product there is in the image and provide similar products.
Although I have written code to detect full pose using mediapose in one of the jupyter notebooks, I have not integrated this into my pipeline. [ You can find the code notebook here ]
CHANGE IN OBJECT DETECTION COMPONENT:
In the paper they are doing the processing of this object detection component offline and not real time processing. Hence, they have preferred to pick a model with a better mean Average Precision (mAP) score, while disregarding the run-time latency. Hence, they have used MaskRCNN.
But in our application we are asking a user to upload a picture and then we are doing processing for object detection in real time. Hence run time latency is important in our use case so I have chosen to use YOLOv8 for this purpose.
Now let’s dive into details of each component
1) SCRAPING PRODUCT DATA FROM MYNTRA WEBSITE:
I have scrapped the data using Selenium. These are the search terms that I have used in myntra website to get the relevant data:
"Men Topwear Formal", "Men Topwear Casual", "Men Topwear Party", "Men Topwear Ethnic", "Women Topwear Formal", "Women Topwear Casual", "Women Topwear Party", "Women Topwear Ethnic", "Men Bottomwear Formal", "Men Bottomwear Casual", "Men Bottomwear Party", "Men Bottomwear Pyjama", "Women Bottomwear Formal", "Women Bottomwear Casual", "Women Bottomwear Party", "Women Bottomwear Ethnic", "Women One Piece", "Men Footwear Formal", "Men Footwear Casual", "Men Footwear Party", "Men Footwear Sports", "Men Footwear Ethnic", "Women Footwear Formal", "Women Footwear Casual", "Women Footwear Party", "Women Footwear Ethnic", "Women Footwear Sports", "Men Eyewear Sunglasses", "Women Eyewear Sunglasses", "Handbags”.
Note: Here data of categories including ethnic was removed because the STL dataset that we are further using for training our siamese network does not have ethnic wear (i.e indian traditional wear like saree, kurta etc.)
Hence our final outcome after scrapping is a data frame which has 16787 rows and 8 columns which are product_id, product_url, image_url, description, brand, gender, category and type.
[ Scrapped data csv is here ]
2) FULL SHOT IMAGE OR NOT:
I used Mediapipe to do full shot image detection.
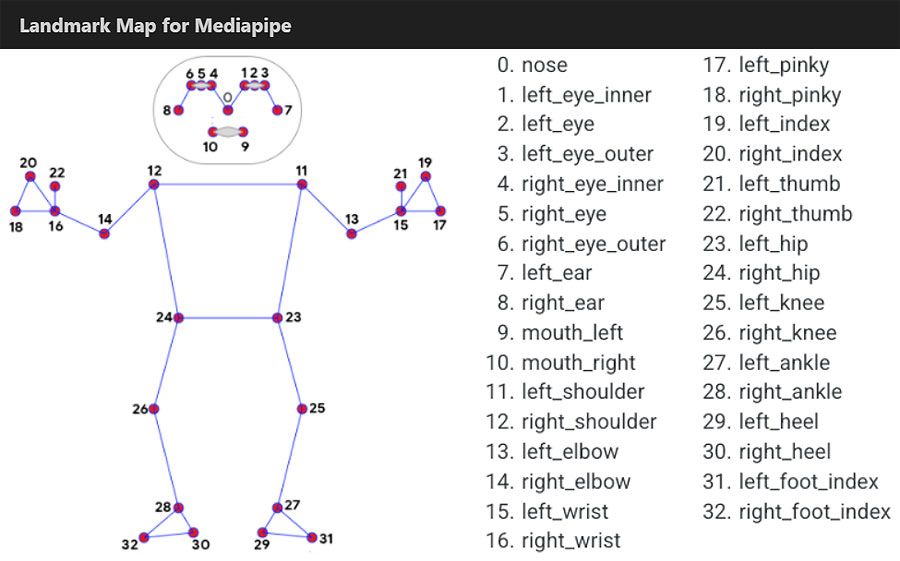
Condition for full shot image:
• Distance between the pair of landmarks 1 and 29 & 4 and 30 should be greater than a (Width of Image/2). [ The full code with working examples is here ]
3) GENDER CLASSIFICATION: [ Dataset used was from kaggle ]
Models that were trained and their best performance:
Custom CNN model: val_loss: 0.6498, val_accuracy: 0.5977, val_precision: 0.5977, val_recall: 0.5977
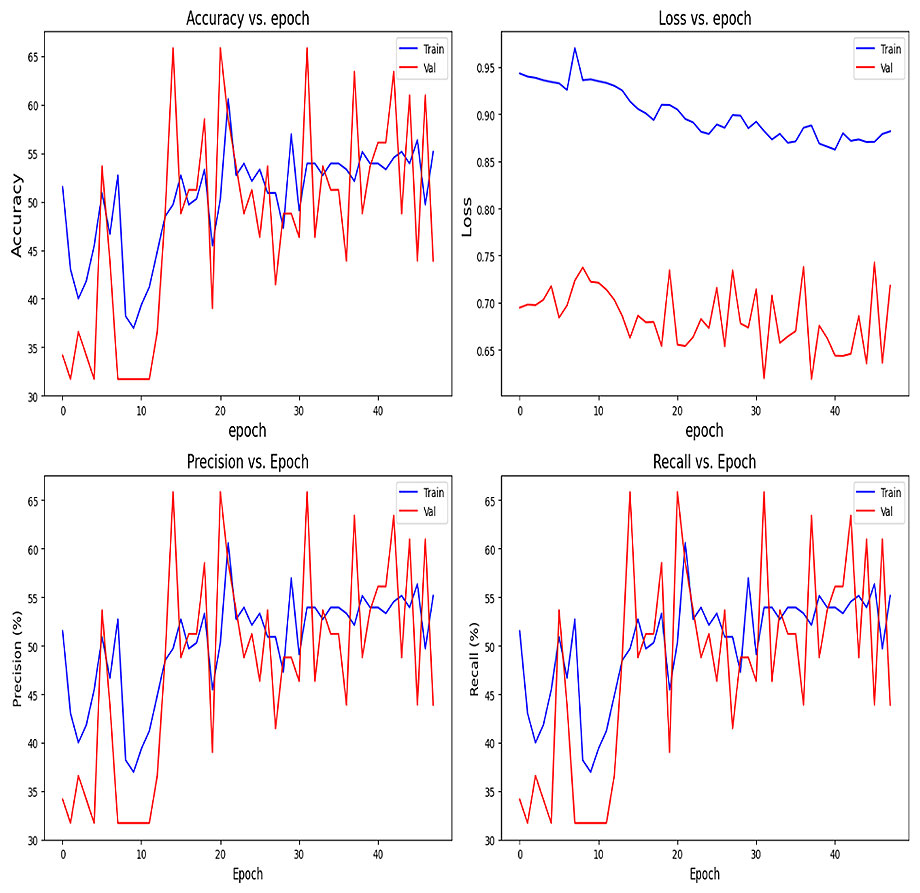
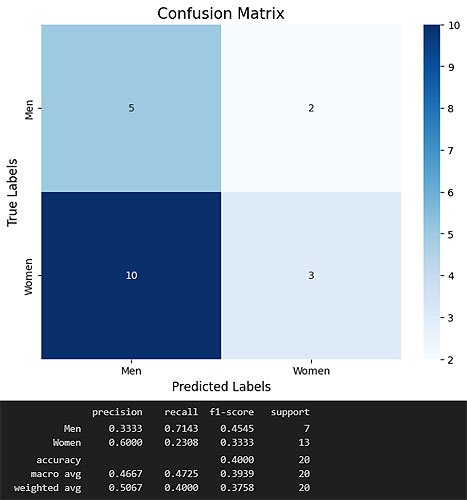
Performance on test set:
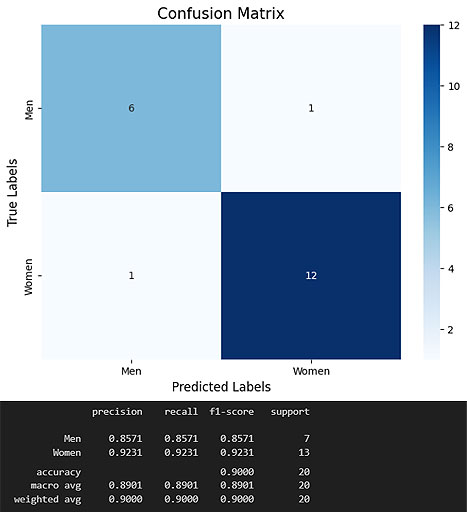
Pretrained Resnet with custom trainable dense layers at the end:
val_loss: 0.2428, val_accuracy: 0.9093, val_precision: 0.9093, val_recall: 0.9093
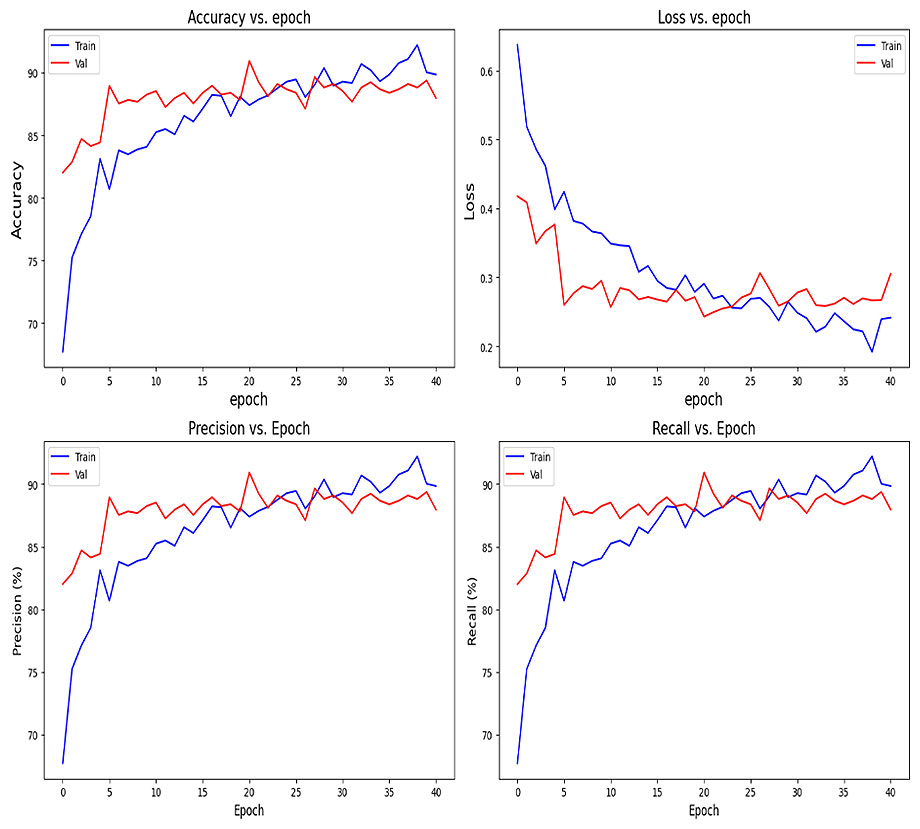
Performance on test set:
[ Code notebook can be found here ]
Pre Trained efficient net B0 with custom trainable dense layers:
val_loss: 0.2032, val_accuracy: 0.9263, val_precision: 0.9263, val_recall: 0.9263
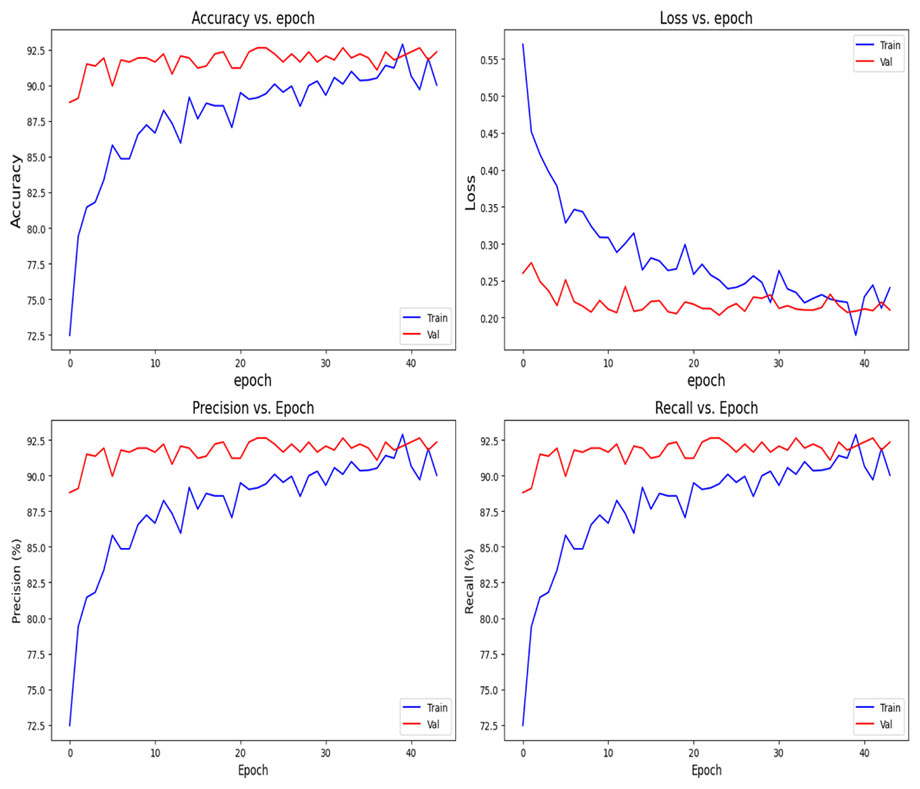
Performance on test set:
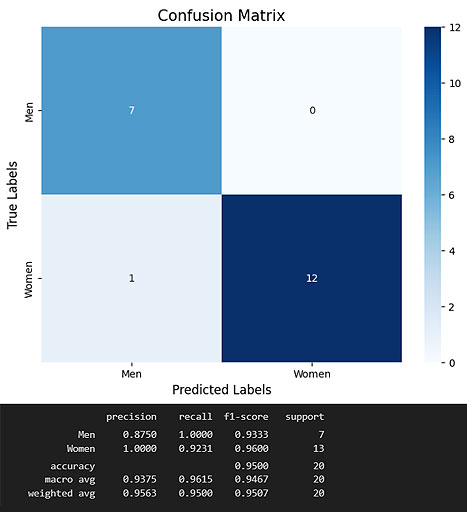
[ Code for this ]
InceptionNetV3 trained with custom layers:
val_loss: 0.3570, val_accuracy: 0.8286, val_precision: 0.8286, val_recall: 0.8286
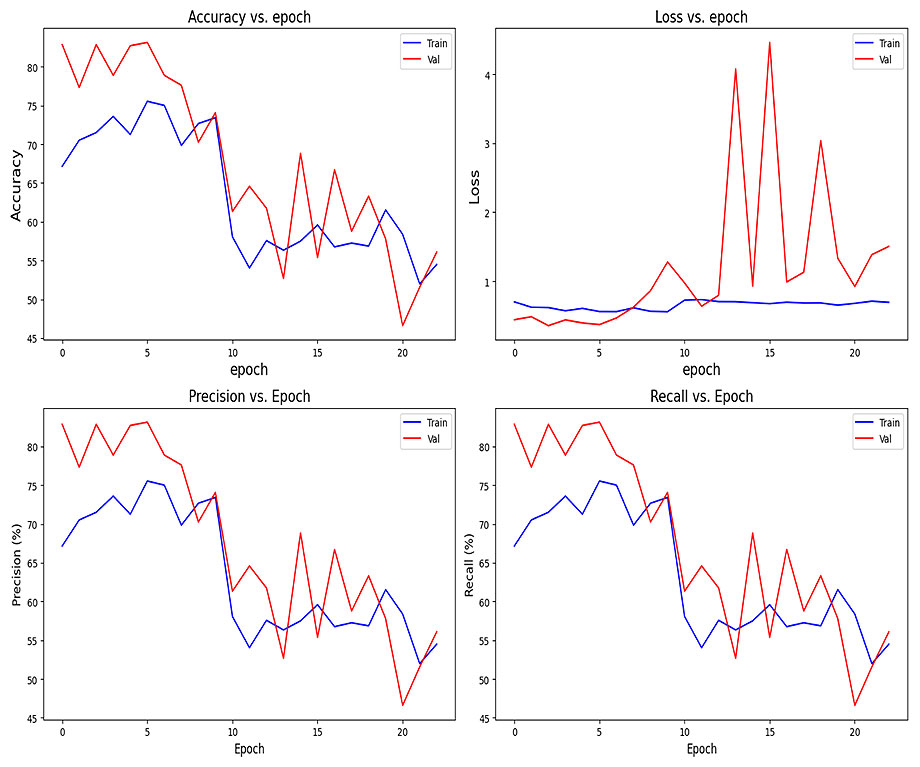
Results on test data:
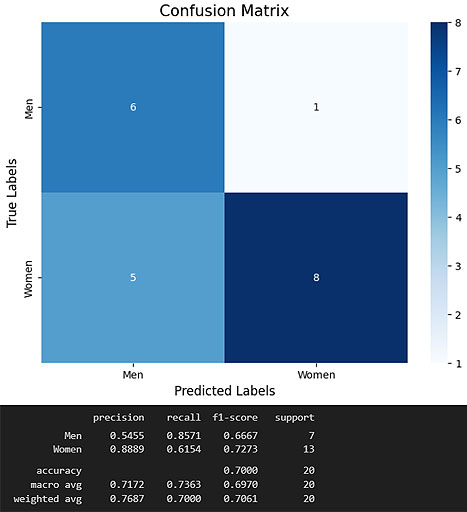
[ Code for this part ]
Best Performing Gender classification model out of them: EfficientNet
4) OBJECT DETECTION MODEL:
I downloaded 472 images of fashion models from the internet and annotated them using Kili. I gave five class labels: topwear, bottomwear, footwear, eyewear and handbags.
TRAINED THE FOLLOWING MODELS:
1. Yolo V8n (nano version)
Here are the results after training this model:
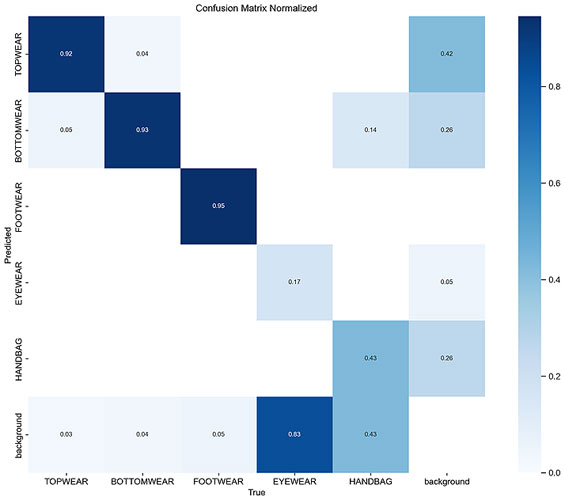
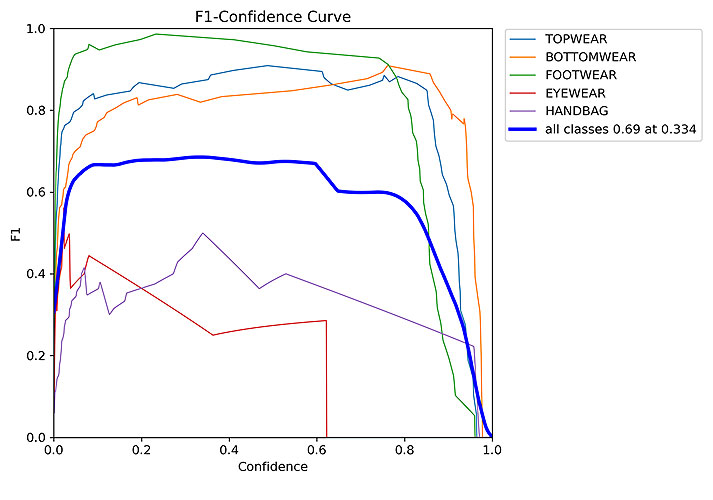
Below I have shared one example of actual vs predicted labels of validation set:


[ Look at all other performance metrics charts ]
2. Yolo V8s (Small Size) trained for 100 epochs
Here are the results after training this model:
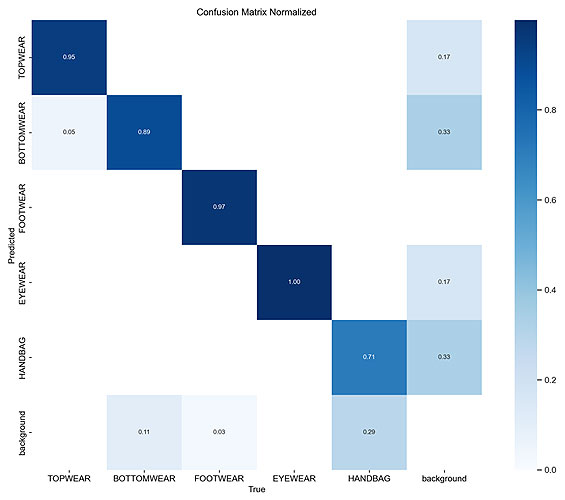
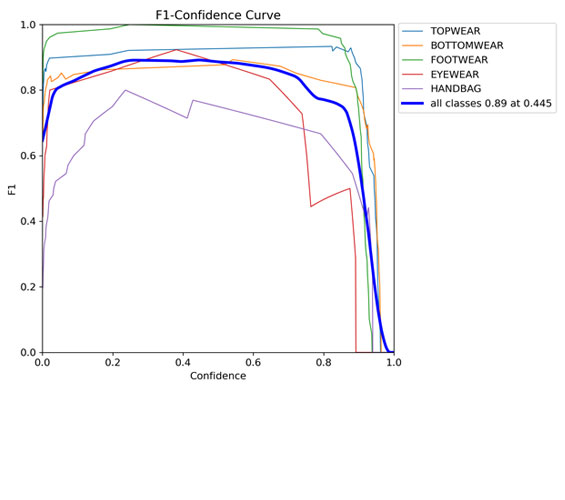
Below I have shared one example of actual vs predicted labels of validation set:


[ Look at all other performance metrics charts here ]
3. Yolo V8l (Large Size)
Here are the results after training this model:
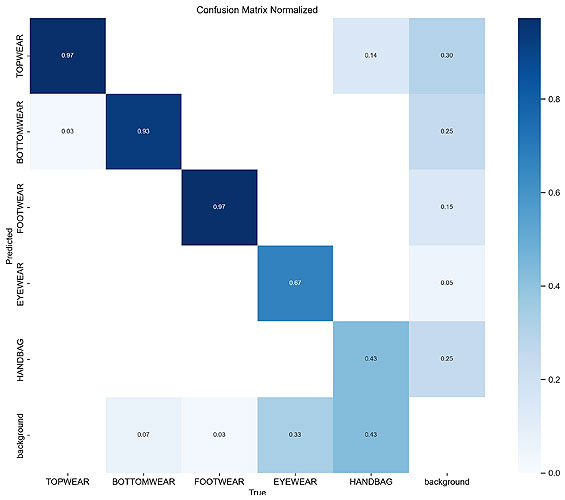
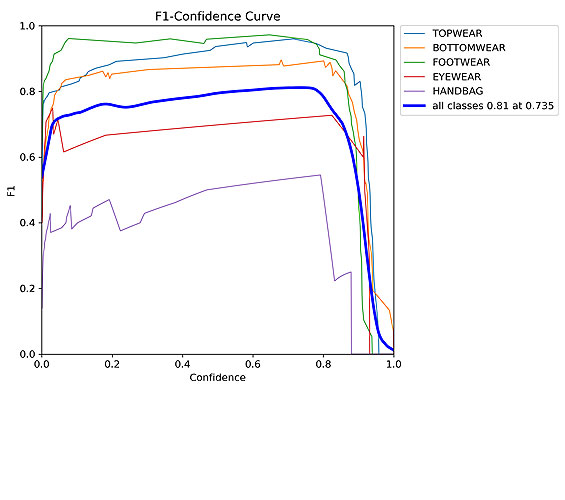
Below I have shared one example of actual vs predicted labels of validation set:


[ Look at all other performance metrics charts here ]
Best performing model: YoloV8s
[ Code where we trained all above mentioned models can be found here ]
[ Code to extract detected objects is here ]
5) DOWNLOADING SHOP THE LOOK DATASET:
[ Downloaded the dataset from here ] and [ STL dataframe downloaded as csv is here ]
This downloaded dataset contains anchor and positive. Negatives are created by randomly assigning not similar items.
Below is the example of how data looks like:

[ Code for this is here ]
6) TRAINING SIAMESE NETWORK ON TRIPLET LOSS - EMBEDDING GENERATING MODELS
These are the Models trained:
1. Trainable Resnet with custom layers
Validation loss on topwear: 0.4793
Validation loss on bottomwear: 0.4013
Validation loss on footwear: 0.4899
Validation loss on eyewear: 0.4964
Validation loss on handbags: 0.4767
Below is the image of distance between anchor embedding & positive embedding and between anchor embedding & negative embedding that our trained model has generated:
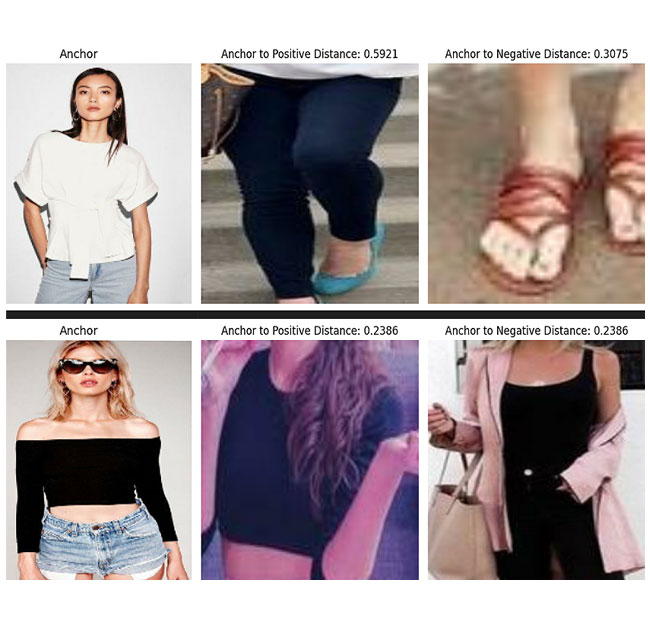


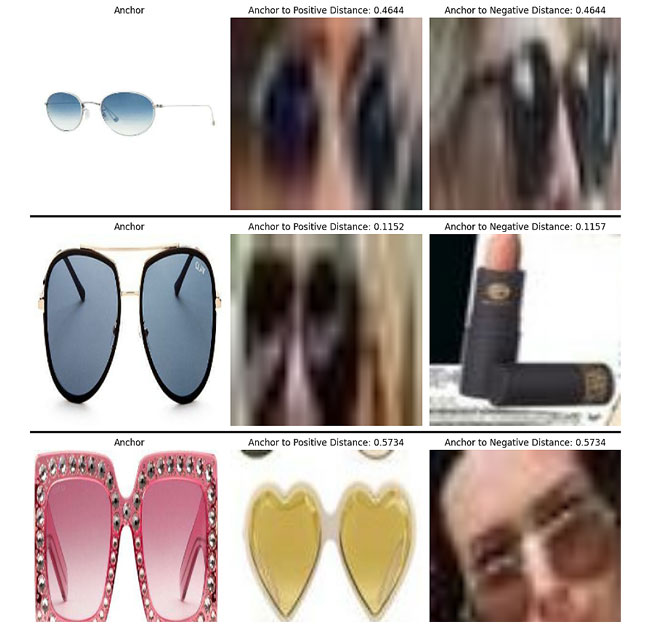
Code is here: [ For topwear ], [ For bottomwear ], [ For footwear ], [ For eyewear ] and [ For handbags ]
2. Pretrained Inception Net with trainable custom layers
Validation loss on topwear: 0.3905
Validation loss on bottomwear: 0.3326
Validation loss on footwear: 0.3382
Validation loss on eyewear: 0.0307
Validation loss on handbags: 0.1035
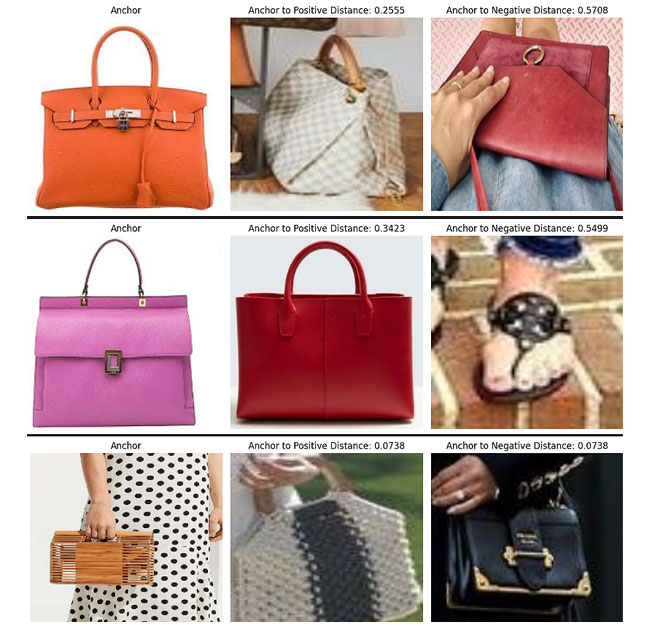
Below is the image of distance between anchor embedding & positive embedding and between anchor embedding & negative embedding that our trained model has generated:





Code is here: [ For topwear ], [ For bottomwear ], [ For footwear ], [ For eyewear ] and [ For handbags ]
3. Pretrained Efficient Net with trainable custom layers
Validation loss on topwear: 0.4647
Validation loss on bottomwear: 0.3566
Validation loss on footwear: 0.4485
Validation loss on eyewear: 0.3169
Validation loss on handbags: 0.2744
Below is the image of distance between anchor embedding & positive embedding and between anchor embedding & negative embedding that our trained model has generated:





Code is here: [ For topwear ], [ For bottomwear ], [ For footwear ], [ For eyewear ] and [ For handbags ]
Best Performing Model: Inception Net
7) GENERATING EMBEDDINGS FOR OUR SCRAPPED PRODUCTS DATA USING OUR TRAINED MODELS:
We are utilizing our scraped data CSV file by accessing images through the image_url column. These images are then passed to our trained models to generate embeddings, which are stored as a new column in the DataFrame. [ Here is the code file doing this ]
8) COMBINING ALL THE COMPONENTS TOGETHER:
Here is the notebook where I have organized the code of components into classes, and then created a main class called FIND_SIMILAR_PRODUCTS. I also gave some images to see the results in this notebook. [ Link to this code notebook ]
The Classes I wrote in the above mentioned
Generate_Embeddings_ForScrappedData notebook is copy pasted into this Find_similar_items.py file with some changes which is specific to displaying the results into streamlit.
[ Here’s the link to the main file that will run the application ]